Teaser
Während unseres Stipendiums an der Akademie für Theater und Digitalität in Dortmund haben wir neue technisch-theatralische Szenarien entwickelt, die auf maschinellem Lernen, Motion-Tracking, Licht und Sound basieren.
Wir untersuchten drei Gebiete: erstens die Sonifizierung von Bewegung, zweitens die Verkörperung digitaler Agenten mit Lichtstrahlen und drittens die Entwicklung von Choreographie unter Verwendung einer virtuellen Umgebung als Probebühne.
Wir haben einen Motion Suit und neue Open-Source-Software-Tools entwickelt, die wir als Ausgangspunkt für neue Erzählungen nutzen werden.


Im letzten Absatz dieser Seite geht es um unsere Zukunftsperspektive: "CapturedBodies" wird eine interdisziplinäre Tanzperformance sein, in der die performenden Körper eine kinetische Lichtskulptur im Raum und ein elektronisches Orchester schaffen.


Dokumentation
1. Sonifizierung der Bewegung
1.1 Abstract
Wir modifizieren verschiedene Körperteile der Performer*in mit digitalen Sensoren, die detaillierte Informationen senden, sodass der Körper selbst zum Instrument wird. Unser Ansatz besteht darin, maschinelles Lernen und künstliche Intelligenz für den Übersetzungsprozess zu nutzen, sodass wir die Assoziationen zwischen Bewegung und Klang in einem spielerischen und explorativen Prozess trainieren können, anstatt sie durch eine lineare Abbildung der Sensordaten auf Klangparameter zu bestimmen. Dies führt zu Assoziationen zwischen Bewegung und Klang, die sich für die Tänzer organisch anfühlen, während gleichzeitig eine kontinuierliche Klangprogression entsteht. Werden die Sensordaten hingegen direkt den Klangparametern zugeordnet, kann dies zu konstruierten Bewegungen führen, die durch das Sensordesign und nicht durch den individuellen Stil des Tänzers bestimmt werden.
1.2 Das Experiment
Wir wollen den Klang mit der Bewegung des Körpers formen. Für die Klangerzeugung sollen keine Mikrofone verwendet werden, sondern digitale Sensoren, die detaillierte Informationen über viele Teile des Körpers senden, so dass der Körper selbst zur Schnittstelle wird. Für die Klangerzeugung verwenden wir digitale Klangsynthesetechniken, die über verschiedene Parameter verfügen, um den Klang mit vielfältigen Kombinationen zu gestalten. Die Herausforderung besteht darin, die Wechselbeziehung zwischen der Körperbewegung und den Parametern des Klangs so zu gestalten, dass sie für die Tänzer*in und das Publikum gleichermaßen sinnvoll ist. Unser Ansatz besteht darin, maschinelles Lernen für den Übersetzungsprozess einzusetzen, so dass wir die Assoziationen zwischen Bewegung und Klang in einem spielerischen und explorativen Prozess trainieren können, anstatt sie mit linearen Zuordnungen zu beschreiben. Indem wir bestimmte Assoziationen zwischen Bewegung und Klang trainieren, formen wir ein Modell, das jede Bewegung mit einem bestimmten Klang interpretiert. Die Tänzer*innen können den Klangraum mit ihren Körpern erkunden und mit den ineinander übergehenden Klängen zwischen den trainierten Assoziationen spielen. Die Frage der musikalischen Komposition und der Choreographie trifft sich im bewegten Körper und dem trainierten Modell - dem latenten Raum.
1.3 Kreative Schleife mit maschinellem Lernen
Im Trainings- und Probenprozess wird eine Klangprogression in einer Schleife abgespielt. Die Tänzer*in findet eine Bewegung, die sich anfühlt, wie mit dem Klang verbunden. Die Bewegungs- und Klangsteuerungsdaten werden aufgezeichnet und bilden die Trainingsdaten für das künstliche neuronale Netz. Der Prozess kann mit verschiedenen Klängen und Bewegungen wiederholt werden, bis eine gewünschte Komplexität und Vielfalt erreicht ist. Dann trainiert die maschinelle Lernsoftware ein Modell, das in der Lage ist, die gelernte Bewegung-Klang-Assoziation zu reproduzieren und den Raum dazwischen mit Kombinationen, Übergängen und unerwarteten Störungen aufzufüllen. Diese neuen Assoziationen können inspirierende Impulse setzen oder den Wunsch wecken, das Modell entsprechend der choreografischen oder kompositorischen Idee weiter zu trainieren und zu formen.

1.4 Technische Fakten
1.4.1 Bewegungsverfolgung
Wir haben einen Motion Suit entwickelt, der die Bewegungen der Performer*in erfasst und sie über WLAN an den Computer sendet. Der Aufbau besteht aus einem Mikrocontroller (ESP32), sechs Gyroskopsensoren (MPU9250), einem Multiplexer, um die Gyroskope mit dem Mikrocontroller zu verbinden, und einer Stromquelle.




Wir verwenden die Orientierungsdaten des Gyroskops als Quaternionen und Geschwindigkeit. Quaternionen sind eine Möglichkeit, Drehungen in einem vierdimensionalen Vektor auszudrücken. Wir verwenden diese Darstellung anstelle von Winkeln, um den Sprung zwischen 360° und 0° zu vermeiden. Dies führt jedoch zu dem Problem, dass in der Welt der Quaternionen jede Drehung zwei Darstellungen hat. Daher müssen wir unsere Trainingsdaten neu aufbereiten, um dieses Problem zu lösen.

1.4.2 Software
Wir verwenden TouchDesigner, um das maschinelle Lernen einzubetten und die Input- und Output-Kommunikation von den Gyroskop-Sensoren und dem Licht, den Projektionen und dem Sound zu handhaben. Für die Klangsynthese verwenden wir AbletonLive mit einigen speziell angefertigten MaxforLive-Patches. Das maschinelle Lernen basiert auf TensorFlow, verpackt in Keras. Unsere gesamte Entwicklung befindet sich auf GitHub und ihr seid herzlich eingeladen, sie zu nutzen: https://github.com/birkschmithuesen/MergingEntities/
1.4.2.1 TouchDesigner
Der Patch besteht aus zwei Teilen "main_learn.toe" und "main_predict.toe". Die Patches können drei Dinge tun: Trainingsdaten aufzeichnen, ein neuronales Netz trainieren und Vorhersagen aus eingehenden Daten treffen. Die Eingabe- und Ausgabekommunikation erfolgt über das OSC-Protokoll.
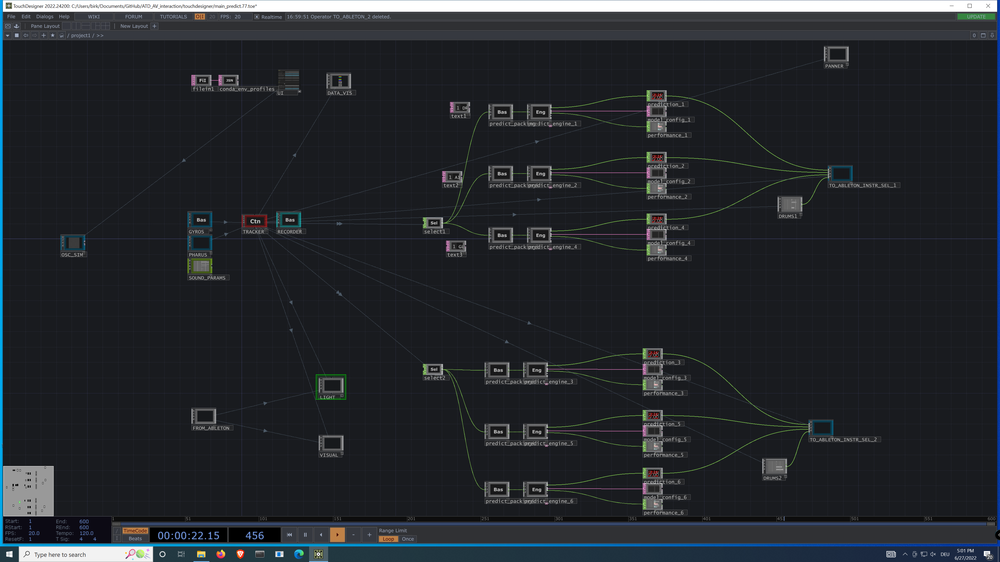
Erstellen eines Datensatzes
Um die Trainingsdaten zu erstellen, zeichnen wir die Bewegungsdaten der Gyroskopsensoren als Eingangsmerkmale zusammen mit den später zu steuernden Klangparametern als Ausgangsziele auf. Die RECORDER-Komponente zeichnet beide Daten zusammen in einer .txt-Datei auf, die dann zum Trainieren des Modells verwendet werden kann.
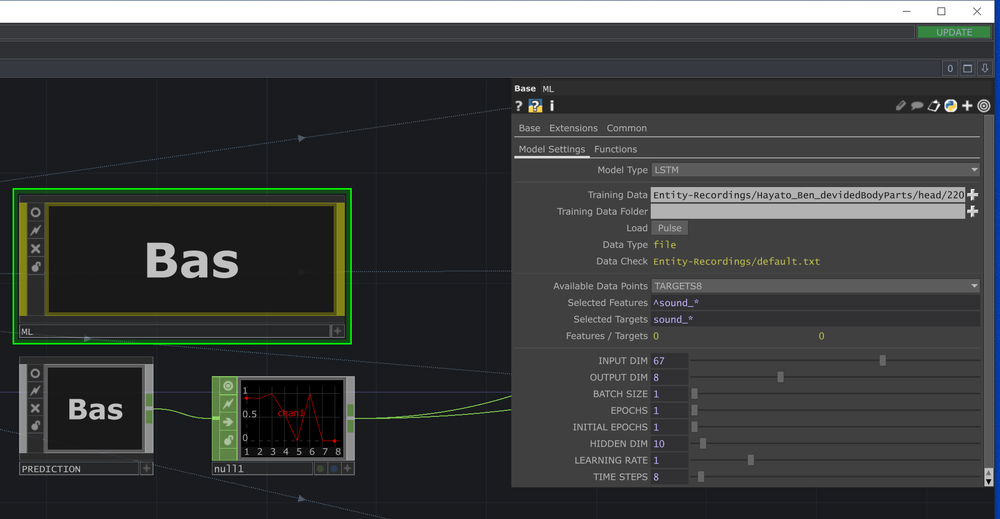
Ein Modell trainieren
Zum Trainieren des Modells verwenden wir die ML-Komponente in der Datei "main_learn.toe". Wir können die Merkmale und Ziele auswählen, die aus den Trainingsdaten zur Verfügung stehen, und entscheiden, welche davon für unseren Zweck relevant sind. Wir können auch den Netzwerktyp, die Anzahl der Epochen für den Trainingsprozess, die Dimension der versteckten Schicht des Netzes, die Lernrate und die Zeitschritte, die eingehalten werden sollen, auswählen. Das Training dauert ein paar Minuten, je nach Grafikkarte und Datenmenge. Weitere Informationen dazu findet ihr im Abschnitt Maschinelles Lernen weiter unten.
Übersetzen von Bewegung in Klang / Vorhersage
Wenn das Modell trainiert ist, findet der Übersetzungsprozess in der Datei main_predict.toe statt. Verschiedene Modelle können parallel ausgeführt werden. Für den Moment haben wir uns eine Architektur ausgedacht, bei der wir für jedes Instrument ein unabhängiges Netzwerk verwenden.
1.4.2.2 Maschinelles Lernen
Bei der Arbeit mit dem künstlichen neuronalen Netz haben wir festgestellt, dass es einige Zeit braucht, um das Verhalten des Materials kennen zu lernen. Während eine Bewegung in nur 10 Epochen gelernt wurde, stieg die Anzahl der benötigten Trainingsepochen schnell an, je mehr Bewegungen wir hinzufügten. Auch die Vorhersagen wurden ungenauer. Das machte es anfangs schwer, Probleme zu finden, weil wir nicht wussten, wozu das Netzwerk mit den richtigen Einstellungen in der Lage war und wo wir einfach an die Grenzen der Kapazität des maschinellen Lernens stießen. Wir lernen immer noch Neues über maschinelles Lernen als künstlerisches Material in einem Performance-Kontext.
Die besten Einstellungen zum Trainieren von vier verschiedenen Bewegungen sind:
Modell-Typ: LSTM
Stapelgröße: 32 - 128 (32 ist besser, aber auch langsamer)
Epochen: 20 - 60 (je weniger Trainingsdaten du hast, desto mehr Epochen benötigst du)
Zeitschritte: 8 (bei mehr wird die Latenzzeit zu groß)
Modell-Typ: lineare Regression
Stapelgröße: 32 - 128 (32 ist besser, aber auch langsamer)
Epochen: 50 - 300 (je weniger Trainingsdaten du hast, desto mehr Epochen benötigst du)
1.4.2.3 KlangSynthese
Für die Klangerzeugung verwenden wir die Software Ableton Live und Max/MSP. Für jeden performativen Körper verwenden wir drei Instrumente, von denen jedes über 3 bis 6 Parameter zur Klangsteuerung verfügt. Diese Parameter werden durch das maschinelle Lernsystem gesteuert. Die Lautstärke jedes Instruments wird durch die Intensität der Körperteile gesteuert, die am meisten an der Bewegung beteiligt sind.

1.5 Learnings
Bei den bisherigen Untersuchungen haben wir festgestellt, dass die Anzahl der verwendeten neuronalen Netze sehr wichtig ist. Wenn jede Klangfolge oder jedes virtuelle Instrument von einem unabhängigen neuronalen Netz trainiert und gesteuert wird, beeinflussen sie sich natürlich nicht gegenseitig, so dass sie sich leicht addieren und zusammen klingen können. Wenn jedoch mehrere Klangverläufe oder virtuelle Instrumente von einem einzigen neuronalen Netz gesteuert werden, hängt das Verhalten stark vom Trainingskonzept ab: Wurde jeweils nur ein Klang oder Instrument geübt, wird in der Vorhersage höchstwahrscheinlich auch nur ein Klang zu hören sein. Sollen Bewegungskombinationen zu Klangkombinationen führen, so muss dies explizit trainiert werden. Dies ist eine wichtige Erkenntnis für die Steuerung des klanglichen Rahmens der kompositorischen Arbeit.
1.6 Neue Fragen und weitere Forschung
Ist es wichtig, dass das Publikum die Verbindung zwischen Bewegung und Klang versteht?
Wie viele Modulationsdimensionen sollte der Klang haben?
Welche Möglichkeiten gibt es, die Lautstärke der Instrumente zu steuern?
Wie können perkussive Klänge mit Bewegungen ausgelöst werden? Wie sehr sollten sie bereits sequenziert sein und welche Art von rhythmischem Einfluss sollte die Performer*in erhalten?

2. Licht Entität
2.1 Abstract
Wir untersuchen die Verkörperung eines Algorithmus mit Lichtbalken. Wir bezeichnen diesen Akteur oder Agenten als digitale Entität und untersuchen verschiedene Bewertungen für sein Verhalten. Unsere Versuchsanordnung besteht aus einem performativen Körper, der der digitalen Entität gegenübersteht, die von einem bis vier beweglichen Köpfen verkörpert wird.
2.2 Tech Facts
Für die Kalibrierung und Steuerung der Movingheads verwenden wir MagicQ und für die Positionsverfolgung LiDAR-Laser mit einer Software namens Pharus vom Ars Electronica Future Lab. Der Algorithmus für das Lichtverhalten ist in TouchDesigner und Python kodiert.

2.3 Verhalten der digitalen Entität
Wir wollten einem digitalen Wesen, das durch Licht und Ton verkörpert wird, ein bestimmtes Verhalten beibringen, damit es als Gegenstück zur peformenden Person agiert. Um diese Idee zu erforschen, untersuchten wir verschiedene Arten von mehr oder weniger autonomen Verhaltensweisen.
1. Die digitale Einheit spiegelt die Bewegungen des Performenden wieder
2. Die digitale Entität spiegelt die Bewegung, reagiert aber mit einer Verzögerung
2. Die digitale Entität bewegt sich autonom, hält aber immer einen Mindestabstand zum Performenden
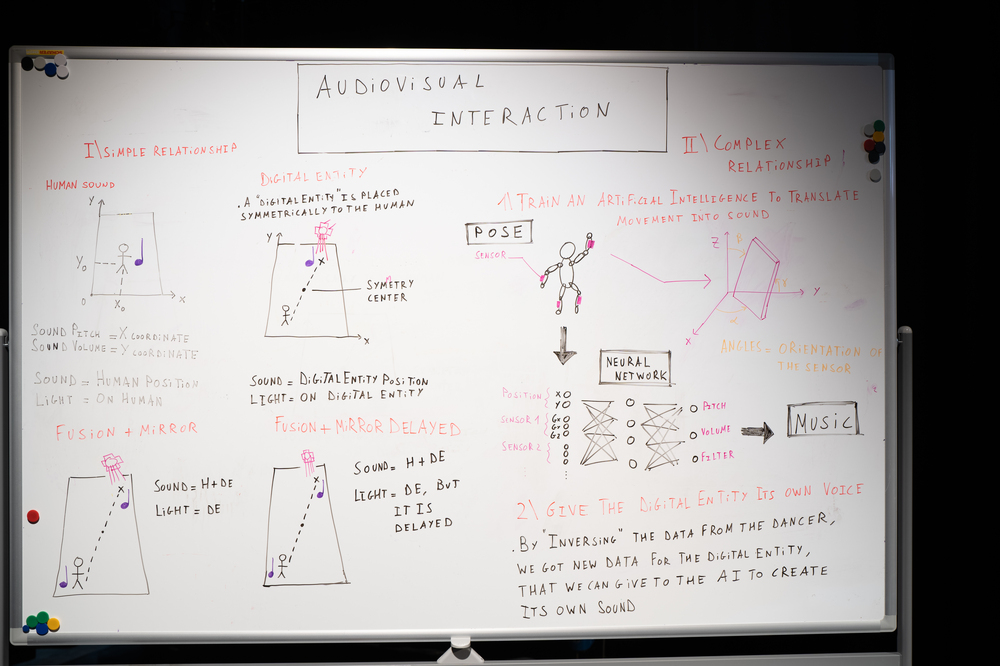
Der Entität ein autonomes Verhalten zu verleihen, ist ein komplexes Problem, das mit einer breiten Palette von Strategien angegangen werden kann. In unserem Experiment haben wir eine Bewertung für die digitale Entität ausprobiert: "Finde den kürzesten Weg, um von der Position der digitalen Entität (dem Lichtstrahl) zur sichersten Position des Feldes zu gelangen. Eine sichere Position wäre definiert durch einen Abstand zum Darsteller, aber auch zu den Grenzen der Bühne."
Hier ist "kurz" im Sinne von Gewicht zu verstehen: Die Länge eines bestimmten Weges ist die Summe der Gewichte der Kisten, die entlang des Weges verwendet werden. Eine einfache theoretische Lösung für dieses sehr häufige Problem im Bereich der Algorithmen (siehe https://en.wikipedia.org/wiki/Shortest_path_problem) ist der Dijkstra-Algorithmus. Er ermöglicht die Konvergenz zu einer effektiven Lösung in einer angemessenen Komplexitätszeit.
2.4 Erkenntnisse und weitere Forschung
Das Konzept, ein digitales Wesen mit einem starken Lichtstrahl zu verkörpern und mit einer performenden Person interagieren zu lassen, ist interessant und könnte als Material für eine Solo-Performance oder interaktive Installation verwendet werden. Wenn wir der digitalen Entität ein natürlicheres und organischeres Verhalten verleihen wollen, müssen wir weitere Funktionen implementieren. Für das digitale Wesen könnte eine detaillierte Partitur geschrieben werden, die sein Verhalten genau beschreibt und dann in Computercode übersetzt wird. Große und langsame Movingheads (wir haben MAC Encore Performance verwendet) sind nicht geeignet, um Menschen zu beleuchten, weil sie nicht schnell genug folgen können. Für den Einsatz auf einer Bühne könnte es hilfreich sein, "Gassenlichter" als Basislichtquelle zu haben und die Movingheads nur für die Lichtskulptur aus Strahlen in der Luft zu verwenden, aber nicht, um den Performenden zu beleuchten.
3. Virtuelle Choreografie
Inspiriert von den Bedingungen vor Ort und Gesprächen mit ehemaligen Stipendiaten haben wir die Motion-Capture-Technologie als digitales Werkzeug zur Entwicklung von Choreografien untersucht.
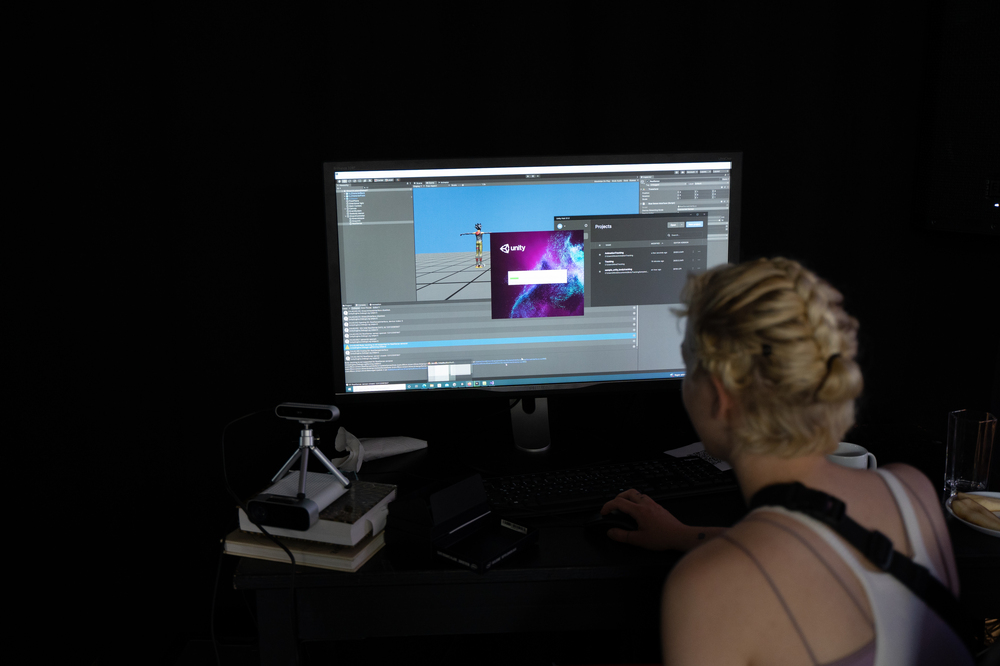
Bei der Bewegungserfassung werden die Bewegungen von Personen oder Objekten digital aufgezeichnet, um sie in eine digitale 3D-Umgebung zu übertragen. Dazu werden physische Mocap-Anzüge, spezielle Kameras und fortschrittliche Software verwendet, um den gesamten Körper präzise zu erfassen.
In einem ersten Versuch haben wir Bewegungen und Posen aufgenommen und mit der Software "Unity" arrangiert.







4. Zukunftsperspektive
Während des Stipendiums konnten wir einige praktische Experimente starten und uns über deren Anwendungen klar werden, aber im Allgemeinen haben wir die Zeit hauptsächlich für die technische Entwicklung genutzt.
Daher widmen wir diesen Abschnitt der Vision, die sich während unserer Zeit an der Akademie herauskristallisiert hat und an der wir in den kommenden Monaten weiter arbeiten möchten.
In Zukunft möchten wir eine Multimedia-Performance für acht oder mehr Performende produzieren. In Vorbereitung darauf wollen wir die Choreographie für die Performenden, den Sound und das Licht auf einer virtuellen Bühne gestalten: Alle Performenden werden als digitale Schauspieler*innen dargestellt und die Interaktion mit Synthesizern und Moving Heads wird simuliert. Ein Pool von Bewegungs- und Klangmaterial wird von Algorithmen generiert und manuell arrangiert. Die Positionen der Performenden und der beweglichen Köpfe werden so berechnet, dass aus Lichtstrahlen geometrische Formen entstehen. Die Formationen der Performenden und damit die Form der kinetischen Skulptur werden algorithmisch beschrieben. Verschiedene Formationen werden zu einer Komposition zusammengefügt und bilden die Grundlage für die choreografische Arbeit.
"CapturedBodies" wird eine interdisziplinäre Tanzperformance sein, in der die auftretenden Körper eine kinetische Lichtskulptur im Raum schaffen. Wir konzipieren den multimedialen Bühnenraum als lebensechtes Gebilde, das mit der Bewegung und dem Standort der Performenden interagiert. Der multimediale Raum, bestehend aus Bewegungsverfolgung, beweglichen Köpfen und Klangsynthese, wird zu einem audiovisuellen Instrument, das von den Performenden gelernt und gespielt wird. Unterstützt durch maschinelles Lernen (KI), verschmelzen Licht, Klangsynthese und Körper zu einer Einheit. Zwischen installativer Medienkunst und modernem Tanz entsteht ein futuristisches Setting, in dem Bewegungs- und Klangmaterial, geometrische Formen aus Lichtstrahlen und maschinelles Lernen die Inszenierung als künstlerisches Material gleichermaßen beeinflussen. In der Arbeit verdichten sich Choreografie und Komposition zu einer Einheit, die durch technische Abhängigkeiten formuliert wird. Es entsteht eine kinetische Skulptur aus Lichtstrahlen und ein elektronisches Orchester.
"CapturedBodies" beschäftigt sich mit der Frage nach Verarbeitung, Nutzung und Risiko durch den Missbrauch von Körperdaten. In der Performance werden die Bewegungsdaten der Performer ausgewertet und die Interpretation der Daten selbst wird zum Gegenstand der Inszenierung. Der körperliche Ausdruck wird durch die Sonifizierung der Bewegungen und Körperdaten erweitert und deren Auswertung durch maschinelles Lernen als künstlerisches Material erforscht.
Im Spannungsfeld zwischen menschlicher Improvisation und technischer Vorgabe verhandeln wir das Verständnis von Willensfreiheit in einer zunehmend algorithmisch bestimmten Welt.
Um diese zukünftige Produktion zu realisieren, sind wir auf der Suche nach Koproduktionspartnern. Bitte kontaktieren Sie uns, wenn dies für Sie interessant klingt.

Team
Nina Maria Stemberger | Birk Schmithüsen | Elisabeth Scholz | Pierre Rodriguez | Daniel Dalfovo | Christian Losert | Ben Petersen | Hayato Yamaguchi
Click the button for more details

Nina Maria Stemberger
Nina Maria Stemberger ist Regisseurin, Performerin, Theaterpädagogin und Kuratorin. Ihre Leidenschaft für Performances im urbanen Raum entwickelte sie 2003 und war bis 2010 in der internationalen Straßentheaterszene präsent. Im Jahr 2008 gründete sie die internationale Jugendbegegnung "artcamp" und war bis 2018 künstlerische Leiterin des Theaterprogramms. Ihre Arbeit konzentriert sich auf ortsspezifische Inszenierungen, partizipatives Publikum und das Crossover zwischen Technologie und Performenden. Es ist ihr wichtig, diese für alle Generationen, Kulturen und Geschlechter zugänglich und durch starke visuelle Darstellungen erfahrbar zu machen. Ihre Produktionen eröffnen neue Perspektiven, machen Theoretisches greifbar, wecken Emotionen und schaffen Solidarität. In ihrer Arbeit stellt sie sich immer wieder die Frage, wie Kunst ein integrativer Bestandteil bei der Entwicklung von Zukunftsperspektiven sein kann und wie sie mitgestaltet werden kann. Sie kuratiert künstlerische Interaktionsarbeiten auf dem Garbicz Festival und dem Chaos Communication Congress.


Birk Schmithüsen
Birk Schmithüsen ist ein Medienkünstler. In seiner künstlerischen Forschung erforscht er komplexe Phänomene wie maschinelles Lernen (AI) und BigData als künstlerisches Material. Die Forschungsergebnisse werden in Performances inszeniert oder in immersiven Medieninstallationen präsentiert. Sein Ansatz ist es, komplexe Systeme durch audiovisuelle Interpretation erfahrbar zu machen und so den Diskurs zu fördern. Zwischen erklärenden Ansätzen durch Datensonifikation und -visualisierung, abstrakter, ästhetischer Wiederverwendung neuer Technologien und spekulativen Konzepten schafft er Systeme mit live-ähnlichem Verhalten und eröffnet neue Perspektiven auf aktuelle Themen. Birk Schmithüsen hat ein Diplom in Bildender Kunst und war Stipendiat der EMAP 2019. Seine Arbeiten werden international auf wichtigen Medienkunstfestivals in Frankreich, den Niederlanden, Spanien, Österreich, Deutschland, Serbien und Brasilien gezeigt, darunter re:publica, Chaos Communication Congress, Ars Electronica Festival und ZKM.

Elisabeth Scholz
Unterstützung bei einem "Unity"-Workshop
Elisabeth Scholz absolvierte ihr Bachelorstudium in Informatik und Medien an der Bauhaus-Universität Weimar. Während ihres Studiums fokussierte sie sich auf Interface Design, Robotik, AR & VR, 3D-Animation und Game Design. Anschließend arbeitete sie ein Jahr lang bei schnellebuntebilder an Projekten im Bereich Interaction Design.
Sie gab einen dreitägigen Workshop in Unity und Blender am Theater Dortmund. Dort arbeitete sie zusammen mit ArtesMobiles an einem Workflow, wie man Animationsclips, die mit einem Motion-Tracking-System aufgenommen wurden, zu einer Choreographie im dreidimensionalen Raum aneinanderreiht. Sie untersuchten auch, wie die Szene mit volumetrischem Licht beleuchtet werden kann.

Pierre Rodriguez
Entwicklung des Gyroskop-Sensoraufbaus
Hallo, ich bin Pierre Rodriguez, der Praktikant von Birk und Nina.
Ich habe im Internet von ihrer Arbeit gehört, und da ich für einige Monate ein Praktikum im Bereich Kunst & KI suchte, habe ich sie kontaktiert, und sie haben mich mitgenommen.
Ich bin also hier, um bei dem elektronischen Teil des Projekts zu helfen, die Anzüge herzustellen und bei anderen Projekten der beiden zu assistieren. Ich würde sagen, es ist schön, mit ihnen zu arbeiten und über das Projekt zu sprechen, denn da es sich um ein Forschungsprojekt handelt, gibt es Raum für Diskussionen und neue Ideen.
Besonders bei der Frage, wie KI Musik macht, gibt es viele theoretische Fragen darüber, wie sie klingen sollte und wie man sie trainiert.

Daniel Dalfovo
Integration des maschinellen Lernens und der Tracking Logik im TouchDesigner
Daniel Dalfovo ist ein in Berlin lebender Medienkünstler. Nach seinem Studium an der Universität der Künste konzentrierte sich seine Arbeit auf die Überschneidung von Kunst, Technologie und Wissenschaft. Aus diesem interdisziplinären Genre entstand eine Reihe von Arbeiten und Kooperationen mit international renommierten Künstlern, Forschungseinrichtungen und Designstudios. Darüber hinaus unterrichtete Daniel Dalfovo an mehreren Universitäten, von Moskau und Shanghai bis Berlin.

Christian Losert
Kodierung des maschinellen Lernens und Max/MSP-Patches
Christian Losert ist Künstler, kreativer Technologe und Dozent im Bereich der Medienkunst. Er studierte Digitale Medien an der Fachhochschule Darmstadt und schloss sein Studium an der Universität der Künste Berlin mit einem Master in Sound Studies ab. Neben seiner Lehrtätigkeit im Bereich Klang- und Medienkunst arbeitete Christian Losert als Klangkünstler und Creative Coder mit namhaften Künstlern, Kreativstudios und wissenschaftlichen Institutionen an international preisgekrönten Arbeiten.

Ben Petersen
Tanz und Maschinentraining
BEN PETERSEN arbeitet als Illustrator, Medienkünstler und Performer. Seine Arbeiten oszillieren zwischen Zeichnung, Animation, Installation, Video, Tanz und Performancekunst. In seinen Arbeiten vereint er die Disziplinen und sucht nach neuen Formen und Räumen. Die Beziehung zwischen Mensch und Natur spielt dabei oft eine Rolle. Seine Videoarbeit "Alleinkommunikation" wurde in Deutschland, Spanien und Portugal gezeigt. Als Performer hat er u.a. mit Elisabeth Schilling, Cie.Willi Dorner, Heike Bröckerhoff und Commedia Futura zusammengearbeitet.

Hayato Yamaguchi
Tanz und Maschinentraining
Hayato Yamaguchi ist ein Tänzer, Choreograf, Lehrer und Straßenkünstler, der in Tokio aufgewachsen ist. Sein Stil basiert auf Contemporary, Jazz, Ballett, Street Dance und Akrobatik. Nachdem er 2012 nach Deutschland kam, war er am Theater Bonn (Kati Farkas, Caroline Finn), Theater Dortmund (Michael Schmieder, Ricarda Regina Ludigkeit), Dance Compagnie Fredeweß (Hans Fredeweß), Deutsche Oper am Rhein (Karl Alfred Schreiner, Anna Holter), TANZ theater INTERNATIONAL 2015, Tanztheater Luxemburg (Jean-Guillaume Weis), Theatre Rites in London (Regie / Sue Buckmaster, Choreograph / Jamaal Burkmar), Tanzmoto dance company in Essen (Gastchoreograph / Royston Maldoom) etc. Seit März 2015 ist er ein potenzieller Künstler (Tänzer) des Cirque du Soleil.



mail: contact@artesmobiles.art
connect with us on:
Signal: signal.artesmobiles.art
Telegram: t.me/artesmobiles