Teaser
During our fellowship at the Academy for Theater and Digitality in Dortmund, we developed new technical-theatrical scenerios based on machine learning, motion-tracking, light and sound.
We explored three areas of interest: first, the sonification of movement; second, the embodiment of digital agents with lightbeams; and third, the development of choreography using a virtual environment as a rehearsal stage.
We developed a motion suit and new open source software tools, that we will use as a starting point for new narratives.


The last paragraph of this site is about our future perspective: "CapturedBodies" will be an interdisciplinary dance performance in which the performing bodies create a kinetic light sculpture in space and an electronic orchestra


Documentation
1. Sonification of movement
1.1. Abstract
We modify various body parts of the performer with digital sensors that send detailed information, so that the body itself becomes an instrument. Our approach is to use machine learning and artificial intelligence for the translation process, so that we can train the associations between movement and sound in a playful and exploratory process, rather than having them determined by a linear mapping of the sensor data to sound parameters. This leads to associations between movement and sound that feel organic to the dancers while creating a continuous progression of sound. On the other hand, if the sensor data is mapped directly to the sound parameters, this can result in engineered movements that are determined by the sensor design rather than the individual style of the dancer
1.2 The experiment
We want to shape the sound with the movement of the body. No microphones are to be used for sound production, but digital sensors that send detailed information about many parts of the body so that the body itself becomes the interface. For the sound generation we use digital sound synthesis techniques, that have various parameters to shape the sound with multiple combinations. The challenge is to design the interrelation between the body movement and the parameters of the sound in a meaningful way for the dancer and the audience alike. Our approach is to use machine learning for the translation process, so that we can train the associations between movement and sound in a playful and exploratory process, instead of describing them with linear mappings. By training certain association between movement and sound, we shape a model that interprets any movement with a specific sound. The dancers can explore the sonic space with their bodies and play with the merging sounds between the trained association. The question of musical composition and choreography meets in the moving body and the trained model - the latent space.
1.3 Creative Loop with the Machine Learning
In the training and rehearsal process a sound progression is played in a loop. The dancer finds a movement, that feels connected to the sound. The movement and sound control data get recorded and form the training data for the artificial neural network. The process can be repeated with different sounds and different movements, till a desired complexity and variety is reached. Then the machine learning software trains a model, that is capable of reproducing the learned movement-sound association and fills up the space in between with combinations, transitions and unexpected glitches. These new associations can set inspirational impulses or create the wish to further train and shape the model according to the choreographic or compositional idea.

1.4 Tech Facts
1.4.1 Movement tracking
We developed a motion suit that can sense the motions of the performer and sends them via wifi to the computer. The set-up consists of a micro-controller (ESP32), six gyroscope sensors (MPU9250), a multiplexer to connect the gyroscopes to the micro-controller and a power-bank.
.




From the gyroscope we use the orientation data as quaternions and the velocity. Quaternions are a way to express rotations in a four dimensional vector. We use this representation instead of angles to avoid the jump between 360° and 0°. But it leads to the problem, that in the quaternions world each rotation has two representation. Therefore we need to reprocesses our training data to tackle that problem.

1.4.2 Software
We use TouchDesigner to embed the MachineLearning and handle the input and output communication from the gyroscope sensors and to the light, projections and sound. For the sound synthesis we use AbletonLive with some custom made MaxforLive patches. The MachineLearning is based on TensorFlow wrapped in Keras. All our development is on GitHub and you are more than welcome to use it:https://github.com/birkschmithuesen/MergingEntities/
1.4.2.1 TouchDesigner
The patch consists of two parts “main_learn.toe” and “main_predict.toe”. The patches can do three things: record training data, train a neural network and make predictions from incoming data. The input and output communication is done via the OSC protocol.
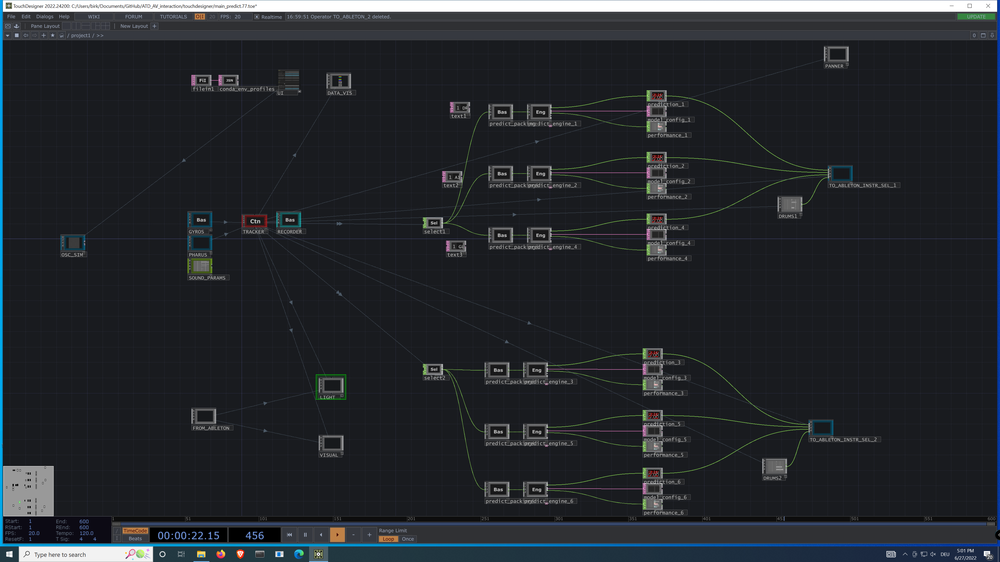
Create a dataset
To create the training data, we record the movement data from the gyroscope sensors as input features together with the sound parameters that should be later controlled as output targets. The RECORDER Component records both data together into a .txt file, that can then be used to train the model.
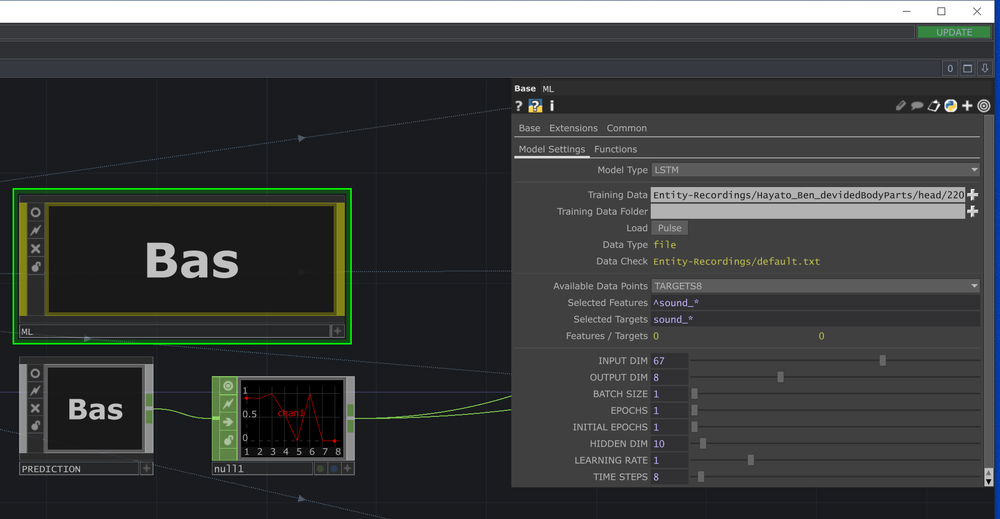
Train a model
For training the model we use the ML Component in the “main_learn.toe”. We can select the features and targets that are available from the trainingdata and choose which ones are relevant for our purpose. We can also choose the type of network, number of epochs for the training process, the dimension of the hidden layer of the network, the learning rate and the time steps that should be observed. The training takes a couple of minutes, depending on the graphic-card and amount of data. For more information see the section Machine Learning further down.
Translate from Movement to Sound / Prediction
When the model is trained, the translation process happens in the main_predict.toe. Different models can be run in parallel. For now we came up with an architecture, where we use one independent network for each instrument.
1.4.2.2 MachineLearning
While working with the artificial neural network we realized, that it needs some time to get to know the behaviour of this material. While a movement was learned in only 10 epochs, the number of training epochs needed increased rapidly as we added more movements. Also the predictions became less accurate. This made it hard to find problems at first because we didn't have a sense of what the network was capable of doing with the right settings, and where we simply reached the limits of machine learning's capacity. We are still learning about machine learning as artistic material in a performance context.
Best settings to train four different movements are:
Model-Type: LSTM
Batch size: 32 - 128 (32 is better, but also slower)
Epochs: 20 - 60 (the less training data you have, the more epochs you need)
Timesteps: 8 (with more it adds too much of a latency)
Model-Type: linear regression
Batch size: 32 - 128 (32 is better, but also slower)
Epochs: 50 - 300 (the less training data you have, the more epochs you need)
1.4.2.3 SoundSynthesis
For sound generation we use the software Ableton Live and Max/MSP. For each performative body we use three instruments, each of which has 3 to 6 parameters for sound control. These parameters are controlled by the machine learning system. The volume of each instrument is controlled by the intensity of the body parts most involved in the movement.

1.5 Learnings
In the research so far we found out that the number of neural networks used is very important. When each sound progression or each virtual instrument is trained and controlled by an independent neural network, they obviously don’t influence each other, so that they can easily add up and sound together. However, if multiple sound progressions or virtual instruments are controlled by a single neural network, the behaviour depends heavily on the training concept: If only one sound or instrument was practised at a time, only one sound will most likely be heard in the prediction as well. If movement combinations are to lead to sound combinations, then this must be explicitly trained. This is an important insight for controlling the sonic framework of the compositional work.
1.6 New questions and further research
Is it important, that the audience understands the connection between movement and sound?
How many modulation dimensions should the sound have?
What possibilities exists, to control the volume of the instruments?
How can percussive sounds be triggered with movements? How much should they already be sequenced and what kind of rhythmic influence should the performer get?

2. Light Entity
2.1 Abstract
We examine the embodiment of an algorithm with light beams. We call this actor or agent a digital entity and explore different scores for its behaviour. Our test arrangement consists of a performative body facing the digital entity, embodied by one to four moving heads.
2.2 Tech Facts
To calibrate and control the movingheads we use MagicQ and for the position tracking we use LiDAR Lasers with a software called Pharus from Ars Electronica Future Lab. The algorithm for the lights behaviour is coded in TouchDesigner and Python.

2.3 Digital Entity Behavior
We wanted to teach a digital entity embodied by light and sound a certain behaviour, to act as a counterpart with the performer. To explore this idea, we looked at different types of more or less autonomous behaviours.
1. The digital entity mirrors the movements of the performer
2. The digital entity mirrors the movement, but reacts with a delay
3. The digital entity moves autonomously, but always keeps a minimum distance to the performer
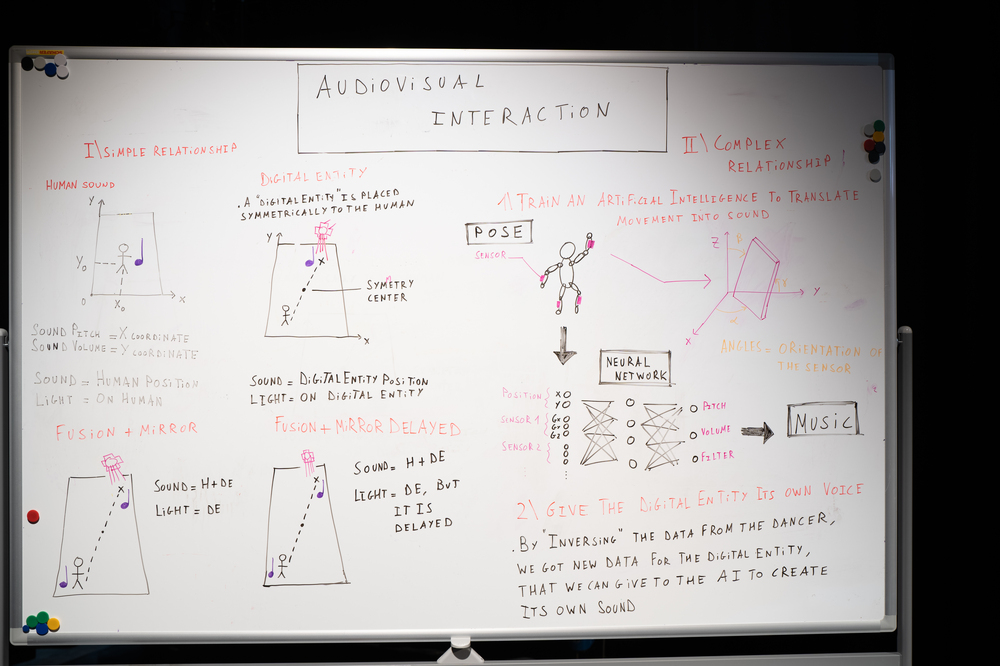
Giving the entity an autonomous behaviour is a complex problem that can be approached with a wide range of strategies. In our experiment we tried one score for the digital entity: "Find the shortest path to get from the digital entities position (the light-beam) to the safest position of the field? A safe position would be defined by having a distance to the performer but also to the boundaries of the stage."
Here, "short" is to be understood in the sense of weight: The length of a given path is the sum of the weights of the boxes used along the way. A simple theoretical solution to this very common problem in the field of algorithms (see https://en.wikipedia.org/wiki/Shortest_path_problem) is Dijkstra's algorithm. It allows to converge to an effective solution in a reasonable complexity time.
2.4 Learnings and further research
The concept to embody a digital entity with a strong light beam and interact with a performer is interesting and could be used as material for a solo-performance or interactive installation. If we want to give the digital entity a more natural and organic behaviour, we need to implement more features. A detailed score could be written for the digital entity, describing its behaviour details and then be translated into computer code. Big and slow movingheads (we used MAC Encore Performance) are not good to light up people, because they can’t follow fast enough. For use in a stage setting, it could be helpful, to have “Gassenlichter” as basic light source and use the movingheads only for the light sculpture from beams in the air, but not to light up the performer.
3. Virtual Choreography
Inspired by the conditions on site and conversations with former fellows, we explored motion capture technology as a digital tool to develop choreography.
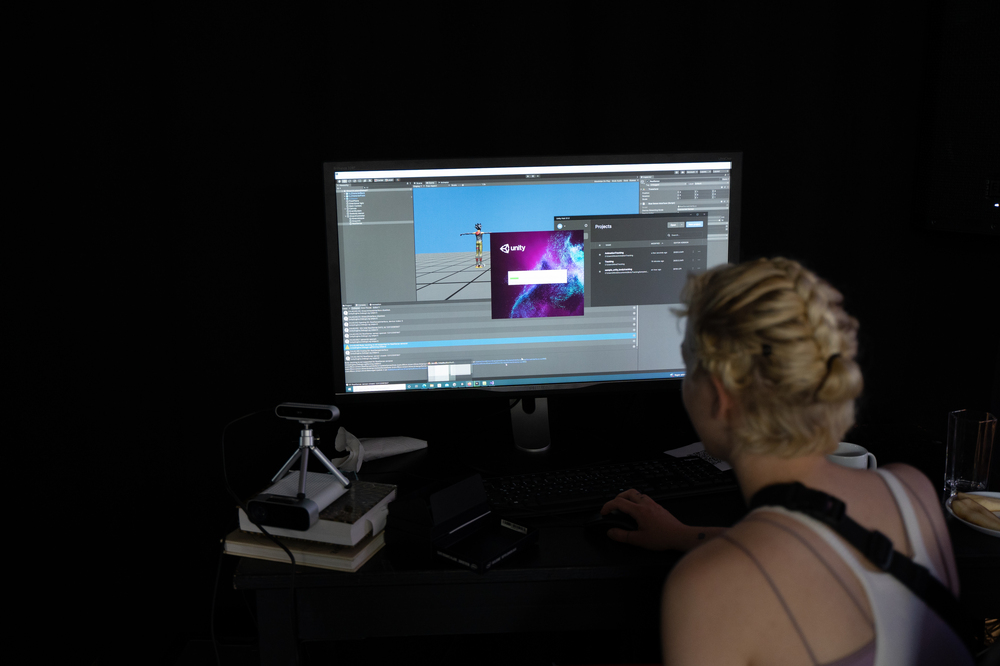
Motion capture is a process of digitally recording the movements of people or objects to transfer them into a digital 3D environment. To do this, physical mocap suits, special cameras and advanced software are used to precisely capture the entire body.
In a first attempt we recorded movements and poses and arranged them with the software "Unity".







4. Future Perspective
During the fellowship we were able to start some practical experiments and become clear about their applications, but in general we used the time mainly for technical development.
Therefore, we dedicate this paragraph to the vision that emerged during our time at the Academy, and which we would like to continue working on in the coming months.
In the future we would like to produce a multimedia performance for eight or more performers. In preparation, we want to design the choreography for the performers, the sound and the light on a virtual stage: All performers will be represented as digital actors and the interaction with synthesizers and moving heads will be simulated. A pool of movement and sound material is generated by algorithms and arranged manually. The positions of the performers and the moving heads are calculated in such a way, that geometric shapes are created from light beams. The formations of the performers and therefore the shape of the kinetic sculpture will be described algorithmically. Different formations are combined to a composition and form the basis for the choreographic work.
"CapturedBodies" will be an interdisciplinary dance performance in which the performing bodies create a kinetic light sculpture in space. We conceive the multimedia stage space as a life-like entity that interacts with the movement and location of the performers. The multimedia space, consisting of motion tracking, moving heads, and sound synthesis, becomes an audiovisual instrument learned and played by the performers. Supported by machine learning (AI), light, sound synthesis and body merge into one. Between installative media art and modern dance, a futuristic setting emerges in which movement and sound material, geometric shapes made of light beams and machine learning equally influence the staging as artistic material. In the work, choreography and composition condense into a unity that is formulated through technical dependencies. A kinetic sculpture of light beams and an electronic orchestra are created.
"CapturedBodies" deals with the question of processing, use and risk through the misuse of body data. In the performance, the performers' movement data are evaluated and the interpretation of the data itself becomes the subject of the staging. The physical expression is expanded through sonification of the movements and body data and its evaluation through machine learning is explored as artistic material.
In the field of tension between human improvisation and technical specification, we negotiate the understanding of freedom of will in an increasingly algorithmically determined world.
To realize this future production, we are looking for co-production partners, so please contact us if this sounds interesting to you.

team
Nina Maria Stemberger | Birk Schmithüsen | Elisabeth Scholz | Pierre Rodriguez | Daniel Dalfovo | Christian Losert | Ben Petersen | Hayato Yamaguchi
Click the button for more details

Nina Maria Stemberger
Nina Maria Stemberger is a director, performer, theatre educator and curator. She developed her passion for performances in urban spaces in 2003 and was present in the international street theatre scene until 2010. In 2008, she founded the international youth encounter “artcamp” and was the artistic director of the theatre programme until 2018. Her work focuses on site-specific stagings, participatory audiences, and the crossover between technology and performers. It is important to her to make these accessible to all generations, cultures and genders and to make them experienceable through strong visual representations. Her productions open up new perspectives, make the theoretical tangible, arouse emotions and create solidarity. In her work, she repeatedly asks herself how art can be an integrative component in the development of future perspectives and how it can be co-designed. She curates artistic interaction works at the Garbicz Festival and the Chaos Communication Congress.


Birk Schmithuesen
Birk Schmithüsen is a media artist. In his artistic research he explores complex phenomena auch as Machine Learning (AI) and BigData as artistic material. The research results are staged in performances or presented in immersive media installations. His approach is to make complex systems experienceable through audiovisual interpretation, thus promoting discourse. Between explanatory approaches through data sonification and visualization, abstract, aesthetic reuse of emerging technologies and speculative concepts, he creates systems with live-like behaviour and opens up new perspectives on current topics. Birk Schmithüsen holds a diploma in fine art and was an EMAP 2019 scholarship holder. His work is shown internationally at key media art festivals in France, Netherlands, Spain, Austria, Germany, Serbia and Brazil, including re:publica, Chaos Communication Congress, Ars Electronica Festival and ZKM.

Elisabeth Scholz
Support with a “Unity” workshop
Elisabeth Scholz completed her bachelor's degree in computer science and media at Bauhaus University Weimar. During her studies she focused on interface design, robotics, AR & VR, 3D animation and game design. Afterwards, she worked at schnellebuntebilder for a year, working on projects in the field of interaction design.
She gave a three-day workshop in Unity and Blender at Theater Dortmund. There she worked together with ArtesMobiles on a workflow on how to string together animation clips recorded with a motion tracking system to create choreography in three-dimensional space. They also explored how to illuminate the scene using volumetric light.

Pierre Rodriguez
Development of the gyroscope sensor setup
Hello, I am Pierre Rodriguez, the intern of Birk and Nina.
I heard about their work on internet and as I was looking for an internship for some months around the Art & AI field, I just contacted them and they took me with them.
So I am here to help with the electronic part of the project, helping to make the suits, and assist for other project of them. I would say it's nice to work and talk with them about the project because since it's a research project, there is place for discussion and new ideas.
Especially on this question of AI making music, there are a lot of theoretical questions about how it should sounds and how to train it, that make it even more interesting when it comes to hear and criticize the outcome we obtain.

Daniel Dalfovo
Integration of the Machine Learning and Tracking Logic in TouchDesigner
Daniel Dalfovo is a Media Artist based in Berlin. After his studies at the University of the Arts his work focused around the intersection of art, technology and science. From this interdisciplinary genre grew a body of work and collaborations with internationally renowned artist, research institutions and design studios. Additionally Daniel Dalfovo taught at multiple universities, ranging from Moscow and Shanghai to Berlin.

Christian Losert
Coding the Machine Learning and Max/MSP patches
Christian Losert is an artist, creative technologist and lecturer in the field of media arts. He studied Digital Media at the Darmstadt University of Applied Sciences and graduated from the Berlin University of the Arts with a Master's degree in Sound Studies. In addition to teaching activities in the field of sound and media art, Christian Losert collaborated as a sound artist and creative coder with renowned artists, creative studios and scientific institutions on international award-winning works.

Ben Petersen
Dancing and Machine Training
BEN PETERSEN works as an illustrator, media artist and performer. His works oscillate between drawing, animation, installation, video, dance and performance art. In his works he unites the disciplines, searching for new forms and spaces. The relationship between man and nature often plays a role. His video work "Alleinkommunikation" was shown in Germany, Spain and Portugal. As a performer he has worked in projects with Elisabeth Schilling, Cie.Willi Dorner, Heike Bröckerhoff and Commedia Futura, among others.

Hayato Yamaguchi
Dancing and Machine Training
Hayato Yamaguchi is a dancer, choreographer, teacher, and street artist, who grew up in Tokyo. His style is based on contemporary, jazz, ballet, street dance and acrobatics. After he moved to Germany in 2012, he was engaged with Theater Bonn (Kati Farkas, Caroline Finn), Theater Dortmund (Michael Schmieder, Ricarda Regina Ludigkeit), Dance Compagnie Fredeweß (Hans Fredeweß), Deutsche Oper am Rhein (Karl Alfred Schreiner, Anna Holter), TANZ theater INTERNATIONAL 2015, Dance Theatre Luxembourg (Jean-Guillaume Weis), Theatre Rites in London (Director / Sue Buckmaster, Choreographer / Jamaal Burkmar), Tanzmoto dance company in Essen (Guest Choreographer / Royston Maldoom) etc. He has been a potential artist (dancer) of Cirque du Soleil since March 2015.



mail: contact@artesmobiles.art
connect with us on:
Signal: signal.artesmobiles.art
Telegram: t.me/artesmobiles